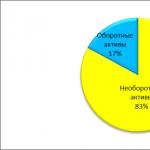
Pour réaliser une analyse quantitative des diagrammes, nous listons les indicateurs du modèle :
· nombre de blocs sur le diagramme – N ;
· niveau de décomposition du diagramme – L ;
· diagramme d'équilibre – B ;
· nombre de flèches se connectant au bloc – A.
Cet ensemble de facteurs s’applique à chaque diagramme modèle. Ce qui suit répertorie les recommandations sur les valeurs souhaitées des facteurs dans le diagramme.
Il faut s'efforcer de faire en sorte que le nombre de blocs sur les diagrammes des niveaux inférieurs soit inférieur au nombre de blocs sur les diagrammes parents, c'est-à-dire qu'à mesure que le niveau de décomposition augmente, le coefficient diminue. Ainsi, une diminution de ce coefficient indique qu'à mesure que le modèle est décomposé, les fonctions doivent être simplifiées et donc le nombre de blocs doit diminuer.
Les diagrammes doivent être équilibrés. Cela signifie que dans le même diagramme, il ne devrait pas y avoir de situation dans laquelle l'œuvre comporte beaucoup plus de flèches entrantes et de flèches de contrôle que de flèches sortantes. Il convient de noter que cette recommandation peut ne pas être observé pour les processus de production qui impliquent l'obtention d'un produit fini à partir d'un grand nombre de composants (fabrication d'une unité de machine, fabrication d'un produit alimentaire, etc.). Par exemple, lors de la description d'une procédure d'assemblage, un bloc peut inclure de nombreuses flèches décrivant les composants d'un produit et une seule flèche quittant le produit fini.
Introduisons le facteur d'équilibre du diagramme :

Il est souhaitable que le coefficient d'équilibre soit minimal pour le diagramme et constant dans le modèle.
En plus d'évaluer la qualité des diagrammes du modèle et du modèle lui-même en général sur la base des coefficients d'équilibre et de décomposition, il est possible d'analyser et d'optimiser les processus métier décrits. La signification physique du coefficient d'équilibre est déterminée par le nombre de flèches connectées au bloc et peut donc être interprétée comme un coefficient estimé basé sur le nombre de documents traités et reçus par un service ou un employé spécifique et fonctions du poste. Ainsi, sur les graphiques de dépendance du coefficient d'équilibre au niveau de décomposition, les pics existants par rapport à la valeur moyenne montrent la surcharge et le sous-travail des salariés de l'entreprise, puisque différents niveaux de décomposition décrivent les activités de divers départements ou salariés. de l'entreprise. Ainsi, s'il existe des pics dans les graphiques des processus métier réels, l'analyste peut alors donner un certain nombre de recommandations pour optimiser les processus métier décrits : répartition des fonctions exercées, traitement des documents et des informations, introduction de coefficients supplémentaires lors de la rémunération des employés.
Effectuons une analyse quantitative des modèles présentés dans les figures 12 et 13, selon la méthodologie décrite ci-dessus. Considérons le comportement du coefficient pour ces modèles. Le diagramme parent « Traitement d'une demande client » a un coefficient de 4/2 = 2, et le diagramme de décomposition a 3/3 = 1. La valeur du coefficient diminue, ce qui indique une simplification de la description des fonctions au fur et à mesure du niveau de le modèle diminue.
Considérons l'évolution du coefficient K b pour deux variantes des modèles.
Pour la première option, illustrée à la figure 20,
![]()
pour la deuxième option
![]()
Le coefficient K b ne change pas de valeur, donc l'équilibre du diagramme ne change pas.
Nous supposerons que le niveau de décomposition des schémas considérés est suffisant pour refléter le but de la modélisation, et dans les schémas du niveau inférieur, les fonctions élémentaires sont utilisées comme noms de travail (du point de vue de l'utilisateur du système) .
En résumant l'exemple considéré, il est nécessaire de noter l'importance de considérer plusieurs options de diagramme lors de la modélisation d'un système. De telles options peuvent survenir lors de l'ajustement des diagrammes, comme cela a été fait avec « Traitement d'une demande client » ou lors de la création d'implémentations alternatives de fonctions système (décomposition du travail « Modification de la base de données »). L'examen des options vous permet de sélectionner la meilleure et de l'inclure dans un ensemble de diagrammes pour un examen plus approfondi.
Pour réaliser une analyse quantitative des diagrammes, nous listons les indicateurs du modèle :
nombre de blocs sur le diagramme - N ;
niveau de décomposition du diagramme - L;
équilibre du diagramme - DANS;
nombre de flèches se connectant au bloc - UN.
Cet ensemble de facteurs s’applique à chaque diagramme modèle. Ce qui suit répertorie les recommandations sur les valeurs souhaitées des facteurs dans le diagramme. Il faut s'efforcer de faire en sorte que le nombre de blocs sur les diagrammes des niveaux inférieurs soit inférieur au nombre de blocs sur les diagrammes parents, c'est-à-dire qu'à mesure que le niveau de décomposition augmente, le coefficient N/L diminue. Ainsi, une diminution de ce coefficient indique qu'à mesure que le modèle est décomposé, les fonctions doivent être simplifiées et donc le nombre de blocs doit diminuer. Les diagrammes doivent être équilibrés. Cela signifie que la situation illustrée sur la figure 1 ne devrait pas se produire dans le même diagramme. 10 : La tâche 1 comporte beaucoup plus de flèches entrantes et de flèches de contrôle que de flèches sortantes. Il convient de noter que cette recommandation peut ne pas être suivie dans les modèles décrivant les processus de production. Par exemple, lors de la description d'une procédure d'assemblage, un bloc peut inclure de nombreuses flèches décrivant les composants d'un produit et une flèche quittant le produit fini. Introduisons le coefficient d'équilibre du diagramme. Il faut s'efforcer de faire en sorte que. Koétait minime pour le graphique. En plus d'analyser les éléments graphiques du schéma, il est nécessaire de considérer les noms des blocs. Pour évaluer les noms, un dictionnaire des fonctions élémentaires (triviales) du système modélisé est compilé. En fait, ce dictionnaire devrait inclure les fonctions du niveau inférieur de décomposition des diagrammes. Par exemple, pour un modèle de base de données, les fonctions « rechercher un enregistrement » et « ajouter un enregistrement à la base de données » peuvent être élémentaires, tandis que la fonction « enregistrement des utilisateurs » nécessite une description plus détaillée. Après avoir constitué un dictionnaire et compilé un ensemble de diagrammes système, il est nécessaire de considérer le niveau inférieur du modèle. S'il existe des correspondances entre les noms des blocs de diagramme et les mots du dictionnaire, cela indique qu'un niveau de décomposition suffisant a été atteint. Le coefficient reflétant quantitativement ce critère peut s’écrire L*C- produit du niveau du modèle et du nombre de correspondances des noms de blocs avec des mots du dictionnaire. Plus le niveau du modèle est bas (L plus grand), plus les correspondances ont de la valeur.
22. Modélisation des données. Architecture Ansi-sparc
De manière générale, les bases de données ont la propriété d'être indépendantes des programmes d'application et, en règle générale, sont représentées par trois niveaux d'architecture : externe, conceptuel et physique ; La base de données est accessible à l'aide d'un SGBD.
L'architecture que nous envisageons est presque totalement cohérente avec l'architecture proposée par le groupe de recherche ANSI/SPARC (Study Group on Data Management Systems). La tâche du groupe était de déterminer si certains domaines de la technologie des bases de données nécessitaient une normalisation (et, si oui, lesquels) et d'élaborer un ensemble d'actions recommandées dans chacun de ces domaines. Au cours du travail sur les tâches assignées, le groupe est arrivé à la conclusion que le seul objet de normalisation approprié était les interfaces et, conformément à cela, il a déterminé l'architecture générale, ou fondement, du système de base de données et a également indiqué rôle important interfaces similaires. Le rapport final (1978) fournissait une description détaillée de l'architecture et de certaines des 42 interfaces spécifiées.
L'architecture divise la SDB en trois niveaux. La perception des données à chaque niveau est décrite à l'aide d'un diagramme. Riz. Trois niveaux d'architecture ANSI/SPARC
Le niveau extérieur est la vue de l'utilisateur individuel. Un utilisateur individuel n'est intéressé que par une certaine partie de l'ensemble de la base de données. De plus, la compréhension de cette partie par l'utilisateur sera certainement plus abstraite par rapport à la méthode de stockage des données choisie. Le sous-langage de données mis à disposition de l'utilisateur est défini en termes d'enregistrements externes (par exemple, une sélection d'un ensemble d'enregistrements). Chaque représentation externe est définie par un schéma externe, qui est principalement constitué de définitions d'enregistrements de chacun des types. présent dans cette représentation externe (par exemple, le type d'enregistrement externe concernant l'employé peut être défini comme un champ de 6 caractères avec le numéro de l'employé, comme un champ de cinq chiffres décimaux destiné à stocker des données sur son salaire, etc.). Une vue conceptuelle est une représentation de toutes les informations d'une base de données sous une forme légèrement plus abstraite (comme dans le cas d'une vue externe) par rapport à une description de la manière physique dont les données sont stockées. Une représentation conceptuelle est définie à l'aide d'un diagramme conceptuel. Pour garantir l'indépendance des données, il n'inclut aucune instruction sur les structures de stockage ou les méthodes d'accès, l'ordre des données stockées, l'indexation, etc. Les définitions du langage conceptuel doivent se référer uniquement au contenu de l’information. Si le schéma conceptuel assure véritablement l’indépendance des données dans ce sens, alors les schémas externes définis sur la base du schéma conceptuel assureront certainement l’indépendance des données. Une vue conceptuelle est une représentation de l'intégralité du contenu d'une base de données, et un schéma conceptuel est la définition d'une telle représentation. Les définitions du cadre conceptuel peuvent également caractériser un grand nombre d'aspects supplémentaires différents du traitement de l'information, tels que les contraintes de sécurité ou les exigences visant à maintenir l'intégrité des données. Le niveau interne est une vue de bas niveau de l'ensemble de la base de données. Un enregistrement interne est un enregistrement stocké. En interne, la représentation est également séparée de la couche physique car elle ne prend pas en compte les enregistrements physiques (communément appelés blocs ou pages). La représentation interne est décrite à l'aide d'un schéma interne, qui définit non seulement les types d'enregistrements stockés, mais également les index existants, la manière dont les champs stockés sont représentés, l'ordre physique des enregistrements, etc.
En plus des éléments des trois niveaux eux-mêmes, l'architecture considérée comprend également certains mappages : Le mappage « conceptuel-interne » établit une correspondance entre la représentation conceptuelle et la base de données stockée, c'est-à-dire décrit comment les enregistrements et les champs conceptuels sont représentés en interne. Lorsque la structure de la base de données stockée change, ce mappage change également, en tenant compte du fait que le diagramme conceptuel reste inchangé. En d’autres termes, pour garantir l’indépendance des données, les effets de toute modification du schéma de stockage ne doivent pas être détectés au niveau conceptuel. Ce mappage sert de base à l'indépendance physique des données si les utilisateurs et les programmes utilisateur sont insensibles aux modifications de la structure physique de la base de données stockée. Une cartographie externe-conceptuelle définit une correspondance entre une représentation externe et une représentation conceptuelle. Ce mappage sert de base à l'indépendance logique des données, c'est-à-dire les utilisateurs et les programmes utilisateur sont immunisés contre les changements dans la structure logique de la base de données (c'est-à-dire que les changements au niveau conceptuel sont implicites). (Par exemple, plusieurs champs conceptuels peuvent être combinés en un seul champ externe (virtuel).) Un mappage externe à externe permet d'exprimer une définition d'une représentation externe en fonction d'une autre sans nécessairement nécessiter une définition explicite du mappage de chaque représentation externe au niveau conceptuel.
Ce type d'analyse repose sur le calcul d'un certain nombre d'indicateurs quantitatifs pour le modèle construit. Il faut tenir compte du fait que ces évaluations sont largement subjectives, puisque l'évaluation est réalisée directement à l'aide de modèles graphiques, et que leur complexité et leur niveau de détail sont déterminés par de nombreux facteurs.
Complexité. Cet indicateur caractérise la complexité hiérarchique du modèle de processus. La valeur numérique est déterminée par le coefficient de complexité k sl .
ksl = ? ur/? ekz
Où? ur -- nombre de niveaux de décomposition,
Ekz -- nombre d'instances de processus.
La complexité du modèle considéré est égale à :
Chez k sl<= 0,25 процесс считается сложным. При k sl =>0,66 n’est pas considéré comme tel. Le processus considéré est de 0,25, ce qui ne dépasse pas le seuil de complexité.
Processivité. Cet indicateur caractérise si le modèle de processus construit peut être considéré comme essentiel (décrit la structure domaine sous la forme d'un ensemble de ses principaux objets, concepts et connexions), ou processus (toutes les instances des processus modèles sont reliées par des relations de cause à effet). En d'autres termes, cet indicateur reflète dans quelle mesure le modèle construit d'une certaine situation dans l'entreprise correspond à la définition du processus. La valeur numérique est déterminée par le coefficient de processus k pr
k pr = ? raz/? garder
Où? raz -- le nombre de « lacunes » (manque de relations de cause à effet) entre les instances de processus métier,
La processivité est égale à
Contrôlabilité. Cet indicateur caractérise l'efficacité avec laquelle les propriétaires de processus gèrent les processus. La valeur numérique est déterminée par le coefficient de contrôlabilité k con
k kon = ? s/? garder
Où? s -- nombre de propriétaires,
Kep -- le nombre d'instances dans un diagramme.
La contrôlabilité est égale à
Lorsque k kon = 1, le processus est considéré comme contrôlé.
Intensité des ressources. Cet indicateur caractérise l'efficacité de l'utilisation des ressources pour le processus en question. La valeur numérique est déterminée par le coefficient d'intensité des ressources k r
kr = ? r/? dehors
Où? r -- le nombre de ressources impliquées dans le processus,
Sortie : nombre de sorties.
L'intensité des ressources est égale à
Plus la valeur du coefficient est faible, plus l'efficacité de l'utilisation des ressources dans le processus métier est élevée.
À k r< 1 ресурсоемкость считается низкой.
Ajustabilité. Cet indicateur caractérise la mesure dans laquelle le processus est régulé. La valeur numérique est déterminée par le coefficient d'ajustabilité k reg
où D est la quantité de documentation réglementaire disponible,
Kep -- nombre d'instances dans un diagramme
L'ajustabilité est égale à
Chez k reg< 1 регулируемость считается низкой.
Les paramètres et les valeurs des indicateurs quantitatifs sont présentés dans le tableau. 7.
Tableau 7. Indicateurs quantitatifs
Pour une évaluation générale du processus analysé, calculez la somme des indicateurs calculés
K = k sl + k pr + k kon + k r + k reg
La somme des indicateurs est égale à
K = 0,1875 + 0,25 + 0,9375 + 0,273 + 0,937 = 2,585
La valeur calculée satisfait à la condition K > 1. Lorsque K > 2,86, le procédé est considéré comme manifestement inefficace. À 1< K < 2,86 процесс частично эффективен.
Pour réaliser une analyse quantitative des diagrammes, nous listons les indicateurs du modèle :
Nombre de blocs sur le diagramme – N;
Niveau de décomposition du diagramme – L;
Solde du diagramme – DANS;
Le nombre de flèches se connectant au bloc est – UN.
Cet ensemble de facteurs s’applique à chaque diagramme modèle. Ce qui suit répertorie les recommandations sur les valeurs souhaitées des facteurs dans le diagramme.
Il faut s'efforcer de faire en sorte que le nombre de blocs sur les diagrammes des niveaux inférieurs soit inférieur au nombre de blocs sur les diagrammes parents, c'est-à-dire avec une augmentation du niveau de décomposition, le coefficient diminuerait . Ainsi, une diminution de ce coefficient indique qu'à mesure que le modèle est décomposé, les fonctions doivent être simplifiées et donc le nombre de blocs doit diminuer.
Les diagrammes doivent être équilibrés. Cela signifie que la situation illustrée sur la figure 1 ne devrait pas se produire dans le même diagramme. 14 : La tâche 1 comporte beaucoup plus de flèches entrantes et de flèches de contrôle que de flèches sortantes. Il convient de noter que cette recommandation peut ne pas être suivie dans les modèles décrivant processus de production. Par exemple, lors de la description d'une procédure d'assemblage, un bloc peut inclure de nombreuses flèches décrivant les composants d'un produit et une seule flèche quittant le produit fini.

Riz. 14. Exemple de graphique déséquilibré
Introduisons le facteur d'équilibre du diagramme :
 .
.
Il faut s'efforcer de Ko,était minime pour le graphique.
En plus d'analyser les éléments graphiques du schéma, il est nécessaire de considérer les noms des blocs. Pour évaluer les noms, un dictionnaire des fonctions élémentaires (triviales) du système modélisé est compilé. En fait, ce dictionnaire devrait inclure les fonctions du niveau inférieur de décomposition des diagrammes. Par exemple, pour un modèle de base de données, les fonctions « rechercher un enregistrement » et « ajouter un enregistrement à la base de données » peuvent être élémentaires, tandis que la fonction « enregistrement des utilisateurs » nécessite une description plus détaillée.
Après avoir constitué un dictionnaire et compilé un ensemble de diagrammes système, il est nécessaire de considérer le niveau inférieur du modèle. S'il existe des correspondances entre les noms des blocs de diagramme et les mots du dictionnaire, cela indique qu'un niveau de décomposition suffisant a été atteint. Le coefficient reflétant quantitativement ce critère peut s’écrire L*C– produit du niveau du modèle par le nombre de correspondances des noms de blocs avec des mots du dictionnaire. Plus le niveau du modèle est bas (plus L), plus les coïncidences sont précieuses.
Méthodologie DFD
La méthodologie DFD repose sur la construction d'un modèle de l'AIS analysé - conçu ou réellement existant. Les principaux moyens de modélisation des exigences fonctionnelles du système conçu sont les diagrammes de flux de données (DFD). Conformément à cette méthodologie, le modèle système est défini comme une hiérarchie de diagrammes de flux de données. Avec leur aide, les exigences sont décomposées en composants fonctionnels (processus) et présentées comme un réseau connecté par des flux de données. Objectif principal Ces outils doivent démontrer comment chaque processus transforme ses entrées en sorties, ainsi qu'identifier les relations entre ces processus.
Les composants du modèle sont :
Diagrammes ;
Dictionnaires de données ;
Spécifications du processus.
Diagrammes DFD
Les diagrammes de flux de données (DFD – Data Flow Diagrams) sont utilisés pour décrire le flux de documents et le traitement de l'information. DFD représente un système modèle en tant que réseau d'œuvres interconnectées qui peuvent être utilisées pour afficher plus clairement les opérations actuelles de flux de documents dans les systèmes de traitement de l'information d'entreprise.
DFD décrit :
Fonctions de traitement de l'information (travail, activités) ;
Documents (flèches), objets, employés ou services impliqués dans le traitement de l'information ;
Tables de stockage de documents (stockage de données, magasin de données).
BPwin utilise la notation Hein-Sarson pour construire des diagrammes de flux de données (Tableau 4).
Notation Hein-Sarson
Tableau 4
Les diagrammes représentent les exigences fonctionnelles utilisant des processus et des magasins connectés par un flux de données.
Entité externe– objet matériel ou individuel, c'est-à-dire une entité en dehors du contexte du système qui est la source ou le destinataire des données du système (par exemple, client, personnel, fournisseurs, clients, entrepôt, etc.). Son nom doit contenir un nom. Les objets représentés par ces nœuds ne devraient participer à aucun traitement.
Système et sous-système lors de la construction d'un modèle d'un SI complexe, celui-ci peut être représenté dans le sens même vue générale sur un diagramme de contexte sous la forme d'un système dans son ensemble, ou peut être décomposé en un certain nombre de sous-systèmes. Le numéro du sous-système sert à l'identifier. Dans le champ Nom, saisissez le nom du système sous la forme d'une phrase avec un sujet et les définitions et ajouts correspondants.
Processus sont conçus pour produire des flux de sortie à partir de flux d’entrée conformément à l’action spécifiée par le nom du processus. Ce nom doit contenir un verbe à la forme indéfinie suivi d'un objet (par exemple, calculer, vérifier, créer, obtenir). Le numéro du processus sert à l'identifier et également à le référencer dans le schéma. Ce numéro peut être utilisé conjointement avec le numéro de diagramme pour fournir un index de processus unique pour l'ensemble du modèle.
Flux de données– les mécanismes utilisés pour modéliser le transfert d’informations d’une partie du système à une autre. Les flux dans les diagrammes sont représentés par des flèches nommées, dont l'orientation indique la direction dans laquelle les informations circulent. Parfois, l’information peut circuler dans une direction, être traitée et revenir à sa source. Cette situation peut être modélisée soit par deux flux différents, soit par un seul flux bidirectionnel.
Fondamentaux de l'analyse quantitative
Analyse quantitative(Analyse quantitative) du marché financier, il s'agit de prévoir les prix et la rentabilité des actifs financiers, d'évaluer les risques liés à l'investissement dans des actifs financiers à l'aide de méthodes mathématiques et méthodes statistiques analyse de séries chronologiques.
À première vue, l’analyse quantitative ressemble à l’analyse technique car les deux types d’analyse utilisent des données historiques sur le prix d’un actif financier et des données historiques sur d’autres caractéristiques de l’actif financier. Mais analyse technique et analyse quantitative il y a une différence significative.
L'analyse technique est basée sur des modèles trouvés de manière empirique. Et ces modèles n'ont pas de stricte justification scientifique.
Alors que les méthodes d'analyse quantitative ont une justification mathématique stricte. De nombreuses méthodes d'analyse quantitative sont utilisées avec succès dans des sciences telles que la physique, la biologie, l'astronomie, etc.
Idéologie de base de l'analyse quantitative
L’idéologie fondamentale de l’analyse quantitative est très similaire à l’approche pratiquée dans les sciences naturelles.
Dans l'analyse quantitative, certaines hypothèses sur le fonctionnement du marché financier sont d'abord avancées. Un modèle mathématique est construit sur la base de cette hypothèse. Ce modèle devrait capturer le plus idée principale l’hypothèse avancée et écarter les détails aléatoires sans importance.
Ensuite, à l’aide de méthodes mathématiques, ce modèle est étudié. Le plus important dans une telle étude est de prévoir les prix des actifs financiers. Une telle prévision peut être faite à la fois pour le moment présent et pour des moments historiques. Ensuite, la prévision est comparée au tableau des prix réels.
Modèle d'analyse quantitative de base
Le modèle d'analyse quantitative le plus important est le modèle de marché financier efficace, qui est formé sur la base de l'hypothèse de marché efficace.
En analyse quantitative, un marché efficace est une situation dans laquelle tous les acteurs du marché financier ont accès à toutes les informations relatives au marché financier à tout moment. Cela signifie que tous les acteurs du marché disposent non seulement toujours de toutes les informations, mais aussi des mêmes informations identiques. Il n’arrive pas qu’un acteur du marché dispose d’informations privilégiées supplémentaires qui seraient inaccessibles aux autres acteurs du marché.
Dans de telles conditions, tous les prix de tous les actifs financiers sont toujours à leurs valeurs d’équilibre. Autrement dit, le prix de tout actif financier sur un marché efficace est toujours égal au prix auquel l’offre et la demande sont égales. Dans un marché efficace, aucun actif financier n’est surévalué ou sous-évalué.
Un marché efficace conduit au fait que dès que les commerçants disposent de nouvelles informations, les prix changent immédiatement et instantanément, en réaction à l'émergence de nouvelles informations. nouvelles informations. Ainsi, les prix sont toujours dans un état d’équilibre, quelle que soit leur évolution.
Par conséquent, d’un point de vue quantitatif, il est impossible de gagner de l’argent sur un marché efficace, comme sur un marché réel, lorsque les investisseurs achètent des actifs sous-évalués et vendent des actifs surévalués. De plus, sur un marché efficace, il n’y a jamais de bulles de marché lorsque le prix évolue à l’opposé de sa valeur d’équilibre.
L'analyse quantitative indique que sur un marché efficace, le prix d'un actif financier change de manière aléatoire, de sorte que le prix le plus probable dans l'instant suivant le temps sera le prix actuel. Et des prix différents du prix actuel seront moins probables. Ce processus aléatoire s’appelle une martingale. (Ne confondez pas martingale et martingale. La martingale est l'une des stratégies de gestion financière. En français, ces deux mots sont des homonymes, c'est-à-dire qu'ils s'écrivent la même « martingale », mais ont des significations différentes.)
Cela signifie que la spéculation à court terme sur les actifs financiers sur un marché efficace est impossible. La seule façon de gagner de l’argent sur un tel marché est d’acheter titres pour une propriété à long terme.
Il s’agit d’une stratégie « acheter et conserver ».
Violation du modèle d'analyse quantitative de base
Si l’hypothèse d’efficience du marché n’est pas respectée, les prix des actifs financiers s’écarteront de leurs valeurs d’équilibre. Ainsi, en fonction de l'une ou l'autre hypothèse de violation du marché efficient en analyse quantitative, l'opportunité s'ouvre de construire des modèles mathématiques permettant de gagner de l'argent sur la différence entre les prix réels et d'équilibre. Les hypothèses spécifiques d'écarts par rapport au modèle de base n'ont souvent pas de justification scientifique stricte en analyse quantitative. Ces hypothèses d’écart par rapport au modèle de base conduisent à différents modèles mathématiques du marché financier. Et, en conséquence, ces modèles mathématiques
Par conséquent, en fonction de l'hypothèse d'écart par rapport au modèle de base de l'analyse quantitative acceptée par les acteurs des marchés financiers, ils commencent à adhérer à l'un ou l'autre modèle de leur comportement sur le marché. À cet égard, la tâche consistant à tester l’efficacité du marché, à déterminer dans quelle mesure le marché diffère du marché efficient, devient très urgente.
Ce problème d'analyse quantitative est résolu à l'aide de méthodes de test statistique des hypothèses qui sous-tendent un marché efficace. Un tel contrôle est possible s'il existe un modèle adéquat qui détermine la rentabilité des actifs financiers soumis à l'équilibre du marché.
Analyse quantitative et psychologie
Sur la base de ce qui précède, il apparaît clairement que sur les marchés financiers, il existe également un lien entre l'analyse quantitative et la psychologie des traders et des investisseurs, comme c'était le cas pour l'analyse technique et l'analyse fondamentale. Prix du marché d'un actif financier peut évoluer dans un sens ou dans un autre selon l'hypothèse d'écart par rapport au modèle de base acceptée par les partisans de l'analyse quantitative, qui possèdent la plus grande quantité d'actifs financiers impliqués dans ce marché.
Analyse quantitative des séries chronologiques
L'analyse quantitative de séries chronologiques implique de grandes difficultés mathématiques. Ces difficultés sont liées à la non-stationnarité statistique du comportement des prix de nombreux actifs d'échange.
Lors de l'étude des séries chronologiques, on considère généralement que la série chronologique des variations des prix d'un actif financier est la somme d'une composante dynamique et d'une composante aléatoire. La composante dynamique dépend des lois économiques fondamentales selon lesquelles le prix devrait évoluer. Et le terme aléatoire est associé à certains facteurs non économiques, par exemple au comportement émotionnel des commerçants, à la publication de certaines nouvelles de force majeure, etc.
La tâche de l'analyse quantitative est d'identifier cette composante dynamique et de filtrer le bruit aléatoire. La composante dynamique identifiée peut être extrapolée dans le futur. Cette extrapolation donne la moyenne du prix prévu. Et le bruit aléatoire filtré permet d'estimer des moments statistiques d'ordre supérieur. Il s’agit avant tout d’un moment statistique de second ordre, c’est-à-dire la dispersion, associée à la volatilité. Connaître la dispersion et la volatilité vous permet d'évaluer les risques.
Ce schéma d'analyse de séries chronologiques est utilisé, par exemple, lors de la recherche de signaux provenant de civilisations extraterrestres parmi le bruit radio cosmique. C’est exactement la tâche à accomplir lorsque le signal dynamique que nous recherchons nous est totalement inconnu.
Mais pour l’analyse quantitative d’une série chronologique de cours boursiers, la tâche est beaucoup plus compliquée. Après tout, les civilisations extraterrestres, connaissant les caractéristiques statistiques et spectrales du bruit radio cosmique, tenteront d'envoyer à l'Univers des signaux qui seront statistiquement et spectralement aussi différents que possible du bruit cosmique. Ils le feront exprès pour permettre aux autres civilisations de rechercher et de reconnaître plus facilement leurs signaux.
Mais le marché financier n’est pas une créature si intelligente. Par conséquent, pour les séries chronologiques de prix, il n’existe pas de séparabilité aussi claire de ces séries en composantes dynamiques et aléatoires. Par conséquent, de nombreuses méthodes mathématiques de filtrage des signaux en analyse quantitative ne fonctionnent tout simplement pas.
En fait, les séries chronologiques de cours boursiers sont la somme de plusieurs séries. La première de ces séries est une série purement chronologique. La dernière série de cette somme est une série purement aléatoire avec une fonction d’autocorrélation nulle. Et les termes intermédiaires sont des séries intermédiaires pour lesquelles la fonction d’autocorrélation disparaît après un certain temps. Et nous avons toute une série de moments où la fonction d’autocorrélation disparaît.
Conclusion
Dans les domaines de l’économie et de la finance, les modèles et méthodes statistiques sont appelés économétrie. D’une part, l’analyse quantitative du marché financier basée sur des modèles et méthodes économétriques est un développement de l’analyse fondamentale traditionnelle dans le domaine de l’incertitude des marchés. D’un autre côté, l’analyse quantitative tente de justifier plus strictement les méthodes d’étude des données historiques. Cela pourrait en outre conduire à un lien plus étroit entre l’analyse quantitative et l’analyse technique.